
Code obfuscation figures among one of the most preferred app code protection and mobile application security techniques to guard against application hacking. It is one of the most recommended AppSec initiatives by security professionals around the world and often takes care of the bare minimum security needs of your application. More often than not, this technique acts as a primary defense mechanism against hacking attempts and guards against common attacks, like code injection, reverse engineering, and tampering with personal information of customers and application users.
Code Obfuscation
Code obfuscation is the modification of executable code so that it is not available for comprehension, interpretation, and execution. The source code itself is obfuscated, so that it becomes unintelligible and impossible for a third-party to understand it, leave alone execute it. Code obfuscation does not impact the application’s interface meant for the end user or the intended output of the code. It is just a precautionary way to render the code unusable for a potential hacker, who may lay their hands over the executable code of an application.
Why is Code Obfuscation Required?
Code obfuscation is particularly useful for open-source applications, which pose a huge disadvantage in terms of hackability of code for personal gains. By making an application hard to reverse engineer, developers ensure that their product’s intellectual property is guarded against mobile app security threats, unauthorized access, and discovery of application vulnerabilities. This process restricts the malicious access to source code, and depending upon the type of obfuscation technique implemented, it ensures varied levels of code protection. The time, cost, and resource factor tilt the scale in favor of abandoning the code when it is obfuscated since the decompiled code is rendered unintelligible.
Types of Code Obfuscation Techniques
Obfuscation acts at multiple levels – it is applied either at the level of semantic structure/lexical code structure or at the level of data structure/control flow. Obfuscation techniques also vary according to the operation they perform on the code. Essentially, the security team, in consultation with the development team, decides which type of obfuscation to employ on the code.
Rename Obfuscation
This technique involves naming variables confusingly so that the original intent of using them is intelligently masked. Methods and variables are renamed using different notations and numbers, which makes it difficult for decompilers to understand the control flow. This obfuscation technique is usually used to obfuscate application code developed in Java, .NET, and Android platforms. This falls under the overall category of layout obfuscation, targeting the source code directly to bring about a defense layer for the application.
Example of a Rename Obfuscation Method

Source: PreEmptive
Data Obfuscation
This technique targets the data structures used in the code, so that the hacker is unable to lay hands on the actual intent of the program. This may involve altering the way data is stored through the program into memory and how the stored data is interpreted for displaying the final output. There are different variants for this technique:
1. Aggregation Obfuscation
This alters the way data is stored in the program. For example, arrays could be broken down into many sub-arrays, which could then be referenced at different places of the program.
2. Storage obfuscation
This changes the very manner in which data is stored in memory. For example, developers can shuffle between local to global storage of variables, so that the real nature of variable behavior is obfuscated.
3. Ordering obfuscation
This method reorders how data is ordered by not altering the behavior of the program/code snippet. Developers accomplish it by developing a separate module which is called for all instances of the variable reference.
4. String encryption
This method encrypts all readable strings and hence results in unreadable code. These need to be decrypted at runtime when the program is executed.
5. Control/Code Flow Obfuscation
How control is passed from one section of the codebase to another plays a critical role in determining the intent of the program. Obfuscating this flow is usually the most remunerative way of confusing mischief at play. This obfuscation method keeps hackers at bay without letting them decipher how and why the code is adopting a particular flow.
One of the most common ways of implementing this obfuscation method is to use arbitrary and unexpected statements, adding unnecessary case-switch statements (dead code) that would never be executed. These statements serve the purpose of nothing more than confusing the intended hacker. This alteration in the order of program execution statements is especially helpful in the case of conditional program orientation.
Example of Control Flow Obfuscation
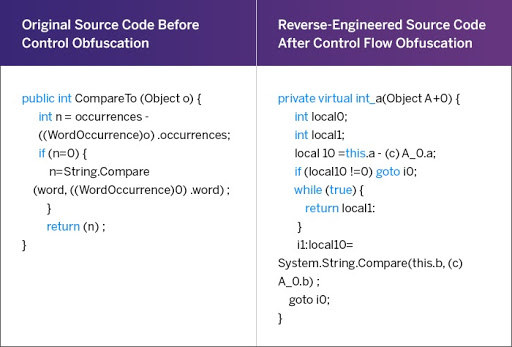
Source: PreEmptive
Debug Obfuscation
Debug information often comes in handy in knowing critical information about program flow, flaws in the program through decompiling, and recompiling source code. It is important to mask such identifiable information by changing their identifiers, line numbers, or stopping the access to debug information altogether.
Address Obfuscation
Attacks that exploit memory programming errors, especially with non-memory safe languages, such as C, C++, have become commonplace. Errors like unchecked array access often result in mobile app security vulnerabilities. The address obfuscation method makes the process of reverse-engineering difficult, as each time the transformed code is executed, the virtual addresses of the code and data of the program are randomized. This makes the effect of most memory-error exploits non-deterministic, with only a very small chance of success.
Example of Address Obfuscation
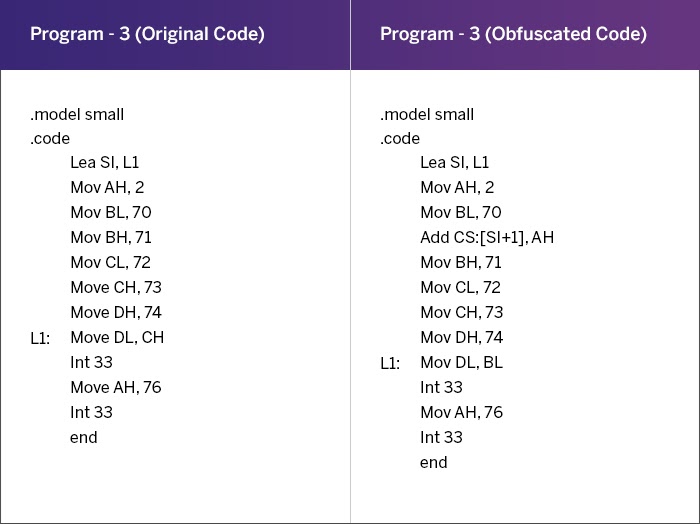
Source: ScienceDirect
Custom Encoding
Using this method, developers encode strings using a custom algorithm and provide a decoder function to get back the original code.
Passing Arguments at Runtime
The program can be changed to expect arguments at runtime. This requires the user to have both the code as well as the decryption key to decrypt the variables.
The security team may also choose to deploy more than one technique concurrently to implement a layered defense approach for protecting applications against different mobile application security threats.
Determining Quality of Obfuscation Method
The success of code obfuscation is dependent on several parameters that determine the quality of code transformation. The quality of an obfuscation technique should be determined by the combination of the following factors:
Strength and resilience
An obfuscated code is only as good as its weakest link. So the best way to check for the quality is to check how much resistance is shown by the obfuscated code when de-obfuscation is tried out. The more effort and time that it requires to break the code, the better the obfuscation.
Differentiation and Potency
This shows the extent to which the obfuscated code is different from the original code. The depth of control flows, nesting levels, and inheritance levels are used to increase the complexity of the source code. The code obfuscation increases this level of complexity.
Stealth
The obfuscated code needs to be indistinguishable from the original source code so that the attacker is confused about the obfuscated section. This makes reverse engineering a difficult proposition to undertake for the attacker. This factor depends from one context to another and is often a crucial factor in evading automated reverse engineering attacks.
Cost
It is defined as the time and resources expended to execute obfuscated code in comparison with the non-obfuscated code. Some performance considerations need consideration while implementing an obfuscated code. An intelligently obfuscated code should serve the purpose of confusing the attacker using prudent techniques and without unnecessarily expending cost/resource.
Does Obfuscation Impact Code Performance?
Since code obfuscation brings about deep changes in the code structure, it may bring about a significant change in the performance of the application as well. In general, rename obfuscation hardly impacts performance, since it is only the variables, methods, and class which are renamed. On the other hand, control-flow obfuscation does have an impact on code performance. Adding meaningless control loops to make the code hard to follow often adds overhead on the existing codebase, which makes it an essential feature to implement, but with abundant caution.
A rule of thumb in code obfuscation is that more the number of techniques applied to the original code, more time will be consumed in deobfuscation. Depending on the techniques and contextualization, the impact on code performance usually varies from 10 percent to 80 percent. Hence, potency and resilience, the factors discussed above, should become the guiding principles in code obfuscation, as any kind of obfuscation (except rename obfuscation) has an opportunity cost.
Most of the obfuscation techniques discussed above do place a premium on the code performance, and it is up to the development and security professionals to pick and choose techniques best suited for their applications. Techniques like binary linking combine multiple input libraries into fewer output libraries. Though this may result in lighter applications and allow a lesser interface for the hackers to play with your app code, decompilation at runtime for code execution becomes a hassle and often increases code execution time. These trade-offs need to be decided upfront, so that a mobile application security roadmap takes them into consideration and adds an appropriate layer of protection while running code into the live environment. In short, the more potent and complex the obfuscation, the greater the performance overhead.
Benefits of Code Obfuscation
Many advantages stem from the way the security team implements code obfuscation in the applications, especially for those hosted on open source platforms. Given the untrusted environment, it is always better to deploy an obfuscated application, which makes it harder for the attackers to review the code and analyze the application. This process ensures that there are no loopholes left for debugging and tampering and redistributing the pseudo application for criminal gains. This layer of protection is especially indispensable for applications dealing with business-critical personal information of consumers.
Most obfuscators also optimize the code by removing not-so-useful metadata, unused dead codes, or duplicate codes. This minification, in turn, speeds up the compilation process and results in quicker code execution and faster results, thus upping the ante on code performance.
Another major advantage accruing out of code obfuscation is that it renders an application hard to reverse-engineer, which means that code deployment in open source platforms is no longer a worry. Iterative code obfuscation is especially famous if multiple layers of security are to be applied. In this technique, the security team applies one or more obfuscation algorithms, with the output of the previous algorithm serving as an input to the next in line and so forth. This way, the attacker can get confused about the original intent of the program and what is visible to them, ultimately resulting in the failure of deobfuscation attempts.
Code obfuscation is a practical way of handling threats and weed out fun-attackers out of the way, as it requires serious effort, skill, resources, and time to crack an obfuscated code. Even if hackers are successful at it, the deobfuscated piece may not resemble the original code much. Though actual measurements in terms of their effectiveness are hard to find, most companies obfuscate code for security as well as proprietary reasons.
The Downside of Code Obfuscation
All the obfuscation techniques do have an impact on the code performance, however minimal. Depending on the part of code obfuscated, and the complexity of algorithms obfuscated, it may involve a good percentage to deobfuscate the code as well.
Most of the automated deobfuscators can reverse-engineer an obfuscated application. While obfuscation can only delay the process of reverse engineering, it does not make it impossible.
Some anti-virus software may also alert their users when they visit a site with obfuscated code, as the obfuscation can also be used to hide malicious code. This may deter users from using legitimate applications and drive them away from trusted corporations.
Should you Obfuscate your Code?
Considering the pros and cons of code obfuscation, a pertinent question is: should you even bother applying code obfuscation? The short answer is: Yes. Code obfuscation, at the very least, transforms a program into a piece of code that is difficult to understand but keeps the functionality intact. The challenges that it poses for reverse engineering and cyber-criminals are reason enough to obfuscate your code. A strong binary-level obfuscation, with advantages accruing to program performance due to code minification, are strong enough reasons for implementing a strategic code obfuscation.
For better results, security experts recommend implementing code obfuscation with other security mechanisms, like code replacement, code tampering detection, runtime application self-protection (RASP), watermarking, encryption, server-side protections, etc. This makes it hard for attackers to complete their activities on time. There are some obfuscation tools available that analyze the application’s runtime behavior to identify performance-sensitive code and indicate those portions of code that could impact performance if strong obfuscation techniques are applied.
Tools for Code Obfuscation
There are a few tools for Android Studio, such as ProGuard and DexGuard. Open-source obfuscators in Java include ProGuard, which is a class file shrinker and removes unused classes. It helps in renaming the remaining classes with meaningless names. The resultant JAR files are hard to reverse-engineer.
Obfuscating Python
PyArmor
This is a command-line interface tool to obfuscate python scripts and bind obfuscated scripts to fixed machine scripts. It helps in the obfuscation of Python scripts by protecting constants and strings and co_code of each function during runtime. It also verifies the license file of obfuscated scripts during execution. It allows developers to replace original python scripts with the obfuscated script seamlessly.
Obfuscating JavaScript
Obfuscator.io
This is a famous tool that obfuscates JavaScript and transforms the original JS file into an altogether new representation, which is harder to understand and re-use, without changing the functionality. It performs different transformations on the code, such as debug protection by disabling console output, variable and function renaming, string removals, dead code injection, and self-defending features. It has a simple-to-use interface, wherein the user uploads the JS file and, based on the level of obfuscation required, chooses the appropriate options – ranging from renaming global variables, rotating or shuffling string arrays, encoding string arrays, performing Unicode on escape sequences by converting all strings to their Unicode representation, etc. It also includes control flow flattening, which hinders comprehension of the program source code. This transformation, though, impacts the code performance by slowing down runtime speed by about 1.5x.
SourceMap
This is another such tool which helps debug the obfuscated JavaScript code. A separate source map may be useful to debug code in the production environment and enables the development team to upload sourcemap to a private location (not known outside).
UglifyJS
It works in CLI mode and has a great variety of options to minify, obfuscate, and beautify JS code. It consists of a parser that produces Abstract Syntax Tree (AST) from JS, mangler component to reduce names of variables and methods to single-letters, and a compressor component that uses transformations to optimize the AST into a smaller one.
One disadvantage of JavaScript is that it cannot be completely deobfuscation-proof. This is because JS essentially runs in the browser, and the browser’s JS engine needs to read it to render the resources. Hence, this capture point cannot be dispensed with.
Obfuscating PHP
PHP Obfuscator by Naneu
This is an obfuscator tool that parses PHP and obfuscates variable names and methods. This library protects PHP from deobfuscators, like UnPHP, and is useful for running code in the native PHP environment.
Yakpro PO
This tool parses PHP code using PHP Parser 4.x and is available as a GIT clone. This results in the PHP compiler being able to understand the redistributed code, but not by humans who may tamper with the source code. It implements control flow obfuscation, removes all comments, indentation, and string literals, iteratively obfuscates the whole program directory, and implements renaming obfuscation.
PHP Compactor library is another open-source library obfuscator tool that compacts and compresses the PHP codebase. Spaces, empty lines, and comments are removed and strings encoded.
Obfuscating HTML
HTML is simply marked-up text which is beautified using HTML tags. Obfuscating HTML is usually done through converting it into JavaScript, converting each HTML line into its corresponding numeric code, or performing a combination of both the methods. Though this is often effective, it increases the negligible size of the pure HTML two to three times, as a code overhead is added at each stage of transformation.
HTML Field Obfuscation (HFO) is often ignored as the traditional security approach focuses primarily on server-side security. Some of the security vulnerabilities are present in-app. Attacks like man-in-the-browser inject scripts to attach themselves to critical fields, like username and password, and tap on the credentials as the users type in. Anti-fraud applications use HFO to prevent scripts from execution.
This approach is designed to confound attacks that use the browser-based application in identifying target fields. In addition to encrypting the field values, decoy fields are also used to distract attackers.
Obfuscating C, C#, and C++
The best way to obfuscate the C code is to compile it and distribute only the binaries. This makes reverse-engineering the distributed code to its original form difficult. C/C++ machine code output after decompilation is itself obfuscated, hence it involves a level of obfuscation built-in. This enables the technical protection of intellectual property.
Another Tool for Language Recognition (ANTRL) is a parser generator which takes C/C++ source code as an input file, captures the implied hierarchy of the input, and transforms it into AST. Based on the structure obtained, each node represents meaningful components of the construct. This becomes a base for implementing the obfuscation algorithm by restructuring the nodes and reviewing its performance and resiliency post obfuscation.
C# code, in comparison to C/C++, can be reverse-engineered more easily. This is because the C# assemblies contain metadata that C++ do not. Also, C# maps to an intermediate language which is easier to decompile to the source code than C/C++. Some features of automated obfuscator tools include user definable list of preserved names, predefined list of reserved names for C#, and stripping comments.
Crypto Obfuscator makes use of sophisticated obfuscation techniques to guard C# code from reverse engineering. These include symbol renaming to unintelligible names, hiding calls from external methods to hide critical methods, string encryption, control flow obfuscation, etc.
Conclusion
All said, code obfuscation in isolation is not enough to handle complex security threats. Though it makes it difficult to deobfuscate code, the availability of automated tools and hackers’ expertise does not make it impossible to reverse-engineer.
Thus code obfuscation is not a one-stop-shop solution for all application security needs. Dependent on the security need, nature of application, and performance benchmark, the dev team could consider implementing a host of code obfuscation techniques in order to protect their code in an untrusted environment. These should be done taking into consideration pros and cons of each technique. This strategy should complement other AppSec initiatives, like encryption, RASP, data retention policies, etc. When used along with RASP tools, like AppSealing, it serves as a powerful antidote against contemporary security threats.
Frequently Asked Questions
1. Is obfuscation the same as encryption?
No, obfuscation and encryption are not the same. Obfuscation is the process of making data hard to interpret. Encryption on the other hand involves converting the content into unreadable format so only authorized users can decode it by applying an encryption key. Obfuscation doesn’t require a key and the content can be deciphered if the original algorithm is known.
2. Is obfuscated code safe?
Obfuscation is a promising security measure that protects against intrusions. Obfuscation however doesn’t guarantee complete security. It should be used only as an additional security layer and cannot be used as a substitute for other security best practices.
3. Can you reverse-engineer obfuscated code?
Obfuscation does not provide complete protection against reverse-engineering. However, obfuscation makes it extremely hard to reverse engineer the code. It only delays the process of reverse engineering.
4. Does obfuscation affect performance?
Obfuscation does have an impact on code performance. However, the impact varies on the type of obfuscation applied. Rename obfuscation doesn’t impact performance whereas control-flow obfuscation can have a considerable impact on code performance.
5. What is an example of obfuscation?
An example of obfuscation is when a software developer intentionally makes the code difficult to understand by using techniques such as renaming variables, removing whitespace, and using complex control structures. This is done to protect intellectual property and prevent reverse engineering of the program.
6. What is the tool to obfuscate code?
An obfuscator is a tool used to obfuscate code by transforming it into a modified version that is difficult to understand and reverse-engineer. It can remove superfluous data, change the structure of the source code, alter how data is stored, and modify the sequence of operations in the code. Advanced obfuscators can further change the structure of the source code.
7. Is code obfuscation worth it?
Code obfuscation is worth it because it makes it harder for hackers to understand and reverse-engineer the code. It involves techniques like removing unnecessary data, changing data formats, and altering the code’s structure. Even if it’s not perfect, it can still significantly increase the time and effort required for unauthorized access, providing extra protection for your software.
8. Is obfuscation better than encryption?
Obfuscation and encryption serve different purposes. Encryption hides the original data, making it reversible with a key, while obfuscation hides the purpose or meaning of data without changing the data itself. Both have their own benefits and are used for different security needs. It’s not a matter of one being better than the other, but rather of using the right method for the specific security requirement.





